

Waarom zou je gestructureerde code schrijven?
In de softwarewereld hoor ik vaak ontwikkelaars praten over een ‘clean software architecture‘. Dat wil zeggen: goed gestructureerde software. Natuurlijk willen we dit allemaal graag implementeren in onze applicaties, maar het blijft vaak onduidelijk hoe we dat precies kunnen doen. Concepten als SOLID, YAGNI, DRY klinken vaak in deze context en al snel weet ik niet meer waar het nu precies om draait. Vandaar ook mijn vragen: Wat definieert nu een ‘clean architecture’? Hoe implementeer je dat in je code? Daar gaat deze series van artikelen over. Ik wil je meer uitleg geven over hoe je goed gestructureerde software kunt schrijven. Dit artikel gaat specifiek in op de vraag: ‘Waarom zou je goed gestructureerde code schrijven?’.
Het doel
Waarom zou je eigenlijk gestructureerde code schrijven? Wat is het hele doel van een ‘clean architecture’? En hoe weet je wanneer je daaraan voldaan hebt? Dat laatste is best simpel. Je code is goed gestructureerd als het voldoet aan de volgende 3 punten:
- Je systeem is flexibel. Dat wil zeggen: aanpassingen in het systeem kunnen makkelijk worden doorgevoerd.
- Je systeem is makkelijk door te ontwikkelen. Komt de eindgebruiker met een nieuwe feature? Geen probleem!
- Het is leuk om met het systeem te werken voor zowel jouzelf als de eindgebruikers.
Als jouw applicatie voldoet aan deze 3 parameters, dan is het een feest om ermee te werken. Stel dat de eindgebruiker met een aanvraag komt voor een aanpassing. Dan hoef je niet uren door code heen te spitten om op elk mogelijke plek de aanpassing door te voeren. Nee, de aanpassing gebeurd in een klein stukje afgesloten code en kan snel worden doorgevoerd. Vervolgens draai je even je tests, verifieer je dat het systeem nog steeds werkt en push je je wijziging naar productie. Vervolgens ga je door met het doorvoeren van meer veranderingen / het implementeren van nieuwe features. Je kunt dus snel nieuwe features ontwikkelen. En dat is het doel van het ontwikkelen van een ‘clean architecture’. Het gaat er dus om dat we sneller nieuwe functionaliteit kunnen toevoegen aan een bestaand systeem.
Ontwikkelsnelheid
Als ik naar mijn eigen applicaties kijk, dan behoren die vaak niet tot bovenstaande categorie. Meestal moet ik een verandering op (heel) veel verschillende plekken doorvoeren. Daardoor kost het extra tijd om het systeem door te ontwikkelen. En dat terwijl ik in het beginstadium van het project veel sneller kon ontwikkelen. Ik denk dat veel softwareprojecten op deze manier starten. In het begin ligt de ontwikkelsnelheid hoog; Nieuwe functionaliteit kan snel worden toegevoegd. Maar, na een aantal weken gaat alles al een stuk langzamer.
Kenmerken slechte structuur
Waarom is dat? Ik kan een paar redenen bedenken:
- De huidige logica is complex. Dat betekent dat het meer tijd kost om de code te begrijpen. Wanneer je vervolgens een aanpassing moet doen in deze logica, kost het dus meer tijd. Je moet immers eerst de context van de code begrijpen, alvorens je het kunt aanpassen.
- De code is afhankelijk van een bepaalde technologie. Stel, je webapplicatie maakt op dit moment gebruik van een MySQL database. Nu moet je ineens je database aanpassen naar een Mongo database. Wanneer de code afhankelijk is van die MySQL database, dan zul je heel veel MySQL-eigen code moeten aanpassen. Dat wil zeggen: het aanpassen van query statements, insert statements enzovoorts. De code is dus rond een bepaalde technologie gebouwd, in plaats van andersom.
- De componenten zijn gekoppeld aan elkaar. Wanneer bepaalde componenten gekoppeld zijn, betekent een verandering in component A vaak ook een verandering in component B. Stel je voor dat je front-end uitgaat van een bepaalde datastructuur die is opgehaald uit de backend. Wanneer je vervolgens die datastructuur aanpast, dan zul je ook de code in de front-end moeten aanpassen. Gekoppelde componenten zorgen er dus voor dat je wijzigingen op meerdere plekken door moet voeren.
De kosten van smerige code
Hierdoor kost het uitbouwen van de applicatie dus meer tijd. En tijd = geld. Vooral als het om softwareontwikkeling gaat. De vraag blijft dan wel: waarom bouwen we zulke applicaties? Ik denk dat een belangrijke reden daarvoor is dat we denken dat een schone architectuur meer tijd kost. En die tijd hebben we meestal niet. We moeten deadlines halen. Daardoor is het het niet waard om veel tijd te steken in het opzetten van een goede structuur. Ik denk dat het het echter wel waard is om hier tijd in te steken.
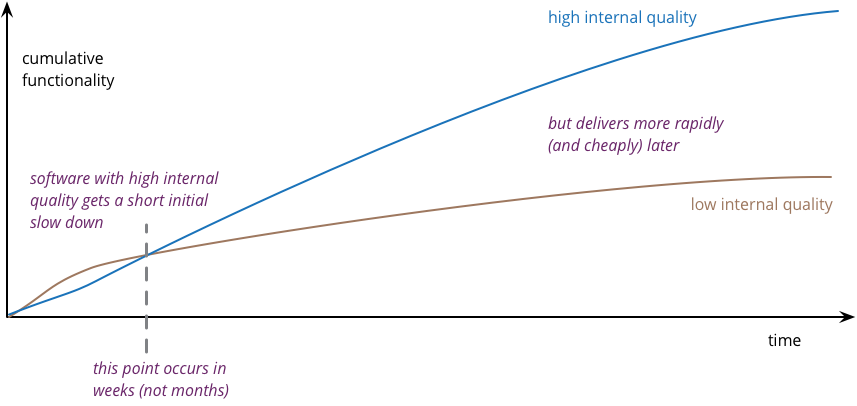
Slecht gestructureerde code
Zie hierboven een grafiek waar de hoeveelheid functionaliteit van een gegeven softwaresysteem is uitgezet tegen de tijd. De blauwe lijn is een software systeem met een zogeheten ‘high internal quality’. Dat is een codebase die een ‘clean architecture’ heeft. De bruine lijn is het tegenovergestelde: een codebase die niet voldoet aan de juiste standaarden. Zoals je ziet kun je in het begin sneller ontwikkelen in het systeem dat smerig is. Dat komt doordat je bepaalde ‘hacks’ kunt toevoegen om het systeem voor nu te laten werken. Dit zijn shortcuts die het systeem dus snel werkend krijgen.
Goed gestructureerde code
Als je een systeem opzet op basis van een modulaire structuur dan kan dat uiteraard niet. Daardoor kun je niet zo snel van start in een schoon systeem als in een smerig systeem. Echter, na een aantal weken gaat de ontwikkeling in het smerige systeem langzamer. Zie hiervoor de redenen hierboven. Zoals je ziet kost het dus op termijn meer tijd en geld om een slechte structuur aan te houden. En dat zijn dus de daadwerkelijke verborgen kosten van rotte code.
Een voorbeeld
Laat ik dat concreet maken met een voorbeeld uit de praktijk. In dit simpele voorbeeld heb ik een applicatie gebouwd waarmee je berichten (posts) kunt aanmaken, wijzigen en verwijderen. Een simpel CRUD-systeem dus. Tijdens het opzetten van deze applicatie focusde ik me direct op de details, niet op de daadwerkelijke functionaliteit. Dus ik begon met het opzetten van een MySQL-database (een detail) en bouwde mijn applicatie rond deze database. Dit is het resultaat.

Ik startte met bovenstaande tabelstructuur. Nadat ik die had aangemaakt, kon ik de representatie van deze structuur in mijn applicatie nabouwen. Dat betekent: een class aanmaken die een Post voorstelt. Dit is in feite wat een ORM (bijvoorbeeld Doctrine of Eloquent) doet.

Vervolgens moest ik de posts uit de MySQL database ophalen en omzetten naar Post-objecten. Hierdoor kon ik namelijk Post-objecten in mijn applicatie gebruiken. Dit is een handige abstractie bovenop een database. Natuurlijk koos ik hierbij voor een repository class. De repository class zorgt ervoor dat je applicatie niet hoeft te weten uit welke databron de data komt. Dat wil zeggen: de applicatie zelf ‘weet’ niet of de data uit een MySQL-database of een simpele HTTP REST API komt. Dit kwam daaruit:

Uiteindelijk gebruikt de applicatie deze class om Post-objecten te tonen aan de eindgebruiker. In dit voorbeeld heb ik dat extreem versimpeld naar een simpele console-output:

Wanneer ik deze code nu uitvoer, krijg ik de volgende uitvoer.

In dit simpele voorbeeld haalt de applicatie berichten op en toont deze die aan de eindgebruiker. Nu zou dit in een ‘echte’ applicatie natuurlijk geen console-output zijn, maar zou er een leuke front-end zijn die de posts op een mooie manier toont. Maar daar gaat het nu even niet om. Nu is de vraag: wat is er mis met deze code? Op dit moment nog niet zoveel, maar dat kan heel snel wel zo zijn. Stel je voor dat de gebruiker ineens de posts wil kunnen ophalen aan de hand van een id, of aan de hand van een description. Dan zou ik 2 nieuwe methods toevoegen aan de PostRepository die de database weer op een bepaalde manier querien. En daar komt het gevaar: op die manier koppel ik mijn code aan de MySQL databasetechnologie. Zou ik nu van database-technologie moeten wisselen, dan moet ik veel code aanpassen. De code is dus minder flexibel geworden.
Details en toegevoegde waarde
Wat is daar mis mee? De koppeling met een MySQL-database is slechts een implementatiedetail. Dit detail voegt geen waarde toe aan deze applicatie, de daadwerkelijke waarde zit in het kunnen opslaan, bewerken en verwijderen van posts. En of dat nu via een MySQL-database gaat of een Mongo database, dat maakt niet uit. Details veranderen sneller dan logica die waarde toevoegd. Dat laatste noemen we ook wel ‘Business logic’. De functionaliteit dat posts kunnen worden opgeslagen zal niet snel wijzigen, gezien dat het hele doel van de applicatie is. Details veranderen (veel) vaker. In het kort: hoe iets gedaan wordt (de details) in een applicatie zal veel sneller veranderen dan wat gedaan wordt (de business logic of toegevoegde waarde). En daarom moeten we onze applicaties zo bouwen dat die makkelijk om kan gaan met verandering in details. Het is dus nodig de details te abstraheren.
De juiste manier
Wat is dan wel de juiste manier om dit te implementeren? Ten eerste zou ik de code niet rond de database moeten bouwen. De database is slechts een plug-in die mij een mogelijkheid tot opslag geeft. Er zijn echter meerdere manieren om data op te slaan: een Mongo database, een HTTP API, een simpel bestandssysteem, noem het maar op. Het specifieke opslaan in een bepaalde database is slechts een detail. En dat moet in de code beter naar voren komen. De code moet dit opslaan als een plug-in zien. Als een interface. Dat ziet er zo uit:

Persistence is dus een service, een plug-in geworden. Om nu persistence via een MySQL-database toe te voegen, stop ik de MySQL-gerelateerde code in een aparte class. Deze specifieke class bevat alle details rondom het opslaan in een MySQL-database:

Omdat persistence nu een plug-in is geworden, kunnen we meerdere implementaties schrijven voor dit concept. Bijvoorbeeld het opslaan van posts in memory. Dit is weer een aparte class die de code bevat om dat mogelijk te maken:

Vervolgens maakt de repository-class gebruik van deze interface om posts op te halen. De Repository weet in dit geval niet meer welke techniek voor opslaan gebruikt maakt. Het ziet geen verschil tussen in-memory opslag of opslag in een database. Onze code is dus gebaseerd op de daadwerkelijke functionaliteit: het ophalen van posts-data en het omzetten naar Post-objecten.

Wanneer ik nu wil veranderen van opslagtechniek, dan hoef ik alleen maar een andere class aan PostRepository mee te geven. In de PostRepository hoeft daarvoor niks veranderd te worden. De veranderingen hoeven dus maar op 1 plek worden doorgevoerd. En dat maakt de code flexibel en onafhankelijk van de details. En dat is wat we willen!
De strijd
Nu we gezien hebben dat een clean architecture iets is wat we altijd moeten nastreven, blijft wel de vraag hoe we dat kunnen doen. Kijk, we hebben natuurlijk altijd deadlines die we moeten halen. Onze managers willen graag dat we zo snel mogelijk zo veel mogelijk functionaliteit in onze software bouwen. Maar, zoals we gezien hebben, kunnen we alleen snel ontwikkelen als we zorgvuldig ontwikkelen. En daar zit een element van strijd: aan de ene kant wordt er van ons gevraagd om zo snel mogelijk dingen te bouwen en aan de andere kant weten we dat we gestructureerd moeten werken.
Snel veel features of zorgvuldig werken?
De vraag is: welke van de 2 kanten is belangrijker? Gaat om het om het implementeren van een ‘Clean Architecture’ of om zoveel mogelijk features bouwen in een zo kort mogelijke tijd? Laten we kijken naar de 2 extremen:
- Zouden we ons alleen focussen op het implementeren van zoveel mogelijk functionaliteit in zo weinig mogelijk tijd, dan zal onze codestructuur slecht zijn. Zouden we dit naar het extreme nemen, dan zou onze structuur dus maximaal slecht zijn en daardoor is onze applicatie onaanpasbaar. We kunnen het systeem dus niet wijzigen wanneer dit van ons wordt gevraagd.
- Zouden we ons focussen op het implementeren van een juiste structuur, dan kost dat uiteraard meer tijd. We kunnen dus minder features implementeren in dezelfde tijd. Echter, ons systeem is nu wel aanpasbaar. We kunnen nu het systeem wel wijzigen wanneer dat van ons wordt gevraagd.
Uit dit voorbeeld blijkt dat de 2e aanpak veel meer waard is. En dus ook belangrijker is. Software die wel werkt, maar die niet aanpasbaar is, is niks waard. Waarom niet? Omdat er altijd wijzigingen in het systeem doorgevoerd moeten worden. Klanten of managers komen altijd met nieuwe wensen en nieuwe aanpassingen. Als het systeem niet wendbaar is om die aanpassingen door te kunnen voeren, is het binnen de kortste keren vervangen door een systeem dat dat wel kan. Daarom is het zo belangrijk om altijd een goede structuur te kiezen boven een werkend systeem.
Conclusie
In dit artikel heb ik je een introductie gegeven in ‘Clean Architecture’. Ik heb je laten zien wat het doel is en een voorbeeld gegeven waarom gestructureerde code zo belangrijk is. In het volgende artikel in deze serie gaat het over de basis van het programmeren: ‘Programming Paradigms’. We gaan kijken wat we als industrie hebben geleerd over softwareontwikkeling sinds de geboorte van de programmeerwereld in 1938.
Wil je nu een webapplicatie laten bouwen die voldoet aan deze standaard? Neem dan contact met mij op, dan kijken we samen wat ik voor je kan betekenen! Als je graag op de hoogte wilt blijven van mijn artikelen, volg dan mijn bedrijfspagina via LinkedIn! Maak je graag gebruik van video’s om over dit soort softwareconcepten te leren? Abonneer je dan op mijn YouTube-kanaal. Wil je meer informatie hebben over dit onderwerp? Dan raad ik je aan het boek ‘Clean Architecture’ te lezen. Aan de hand van dat boek zal ik mijn volgende artikelen over dit onderwerp vormgeven.
Tot volgende keer!